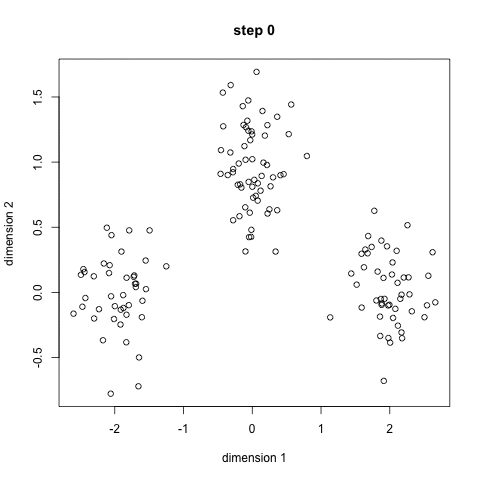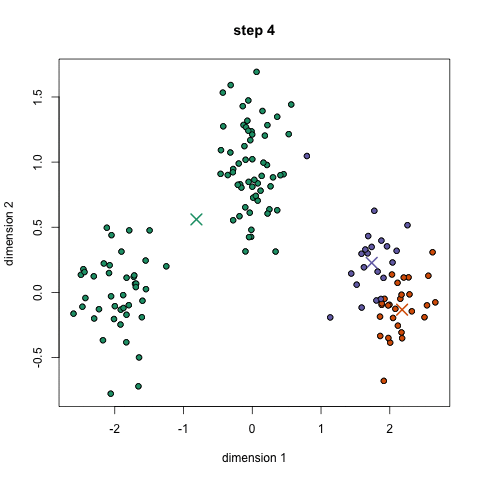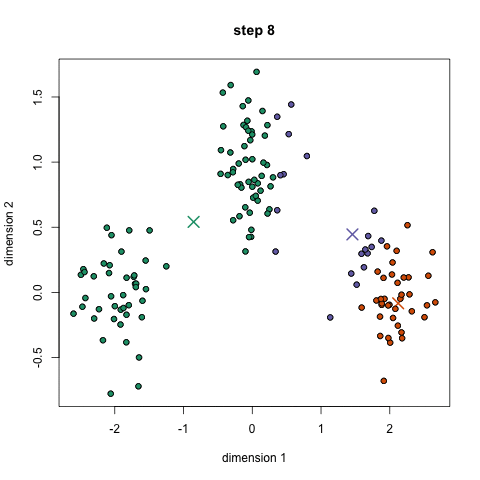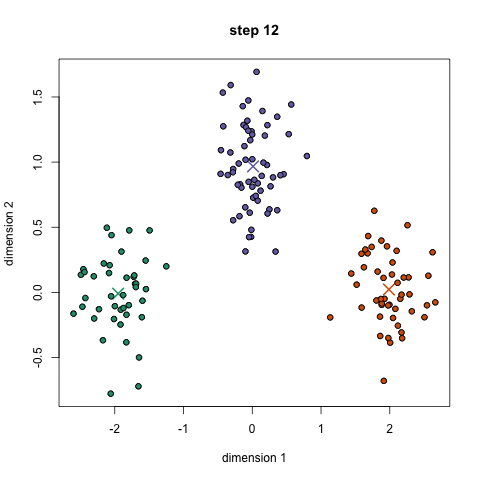
- select a number of classes/groups to use and randomly initialize their respective center points.
- classify each point to be in the group whose center is closest to it.
- recompute the group center by taking the mean of all the vectors in the group.
 |
| Two failure cases for K-Means |
source: The 5 Clustering Algorithms Data Scientists Need to Know
No comments:
Post a Comment