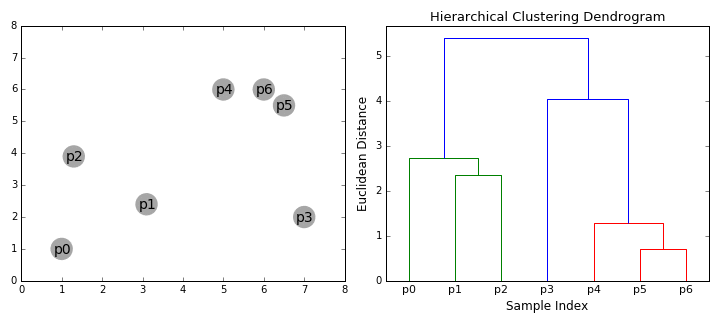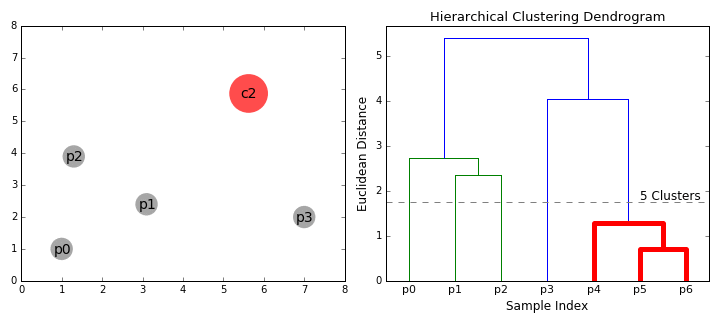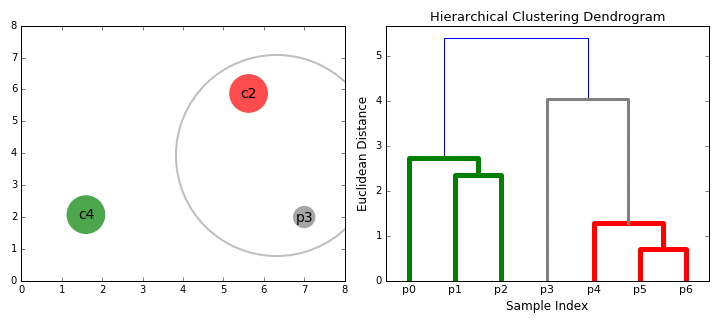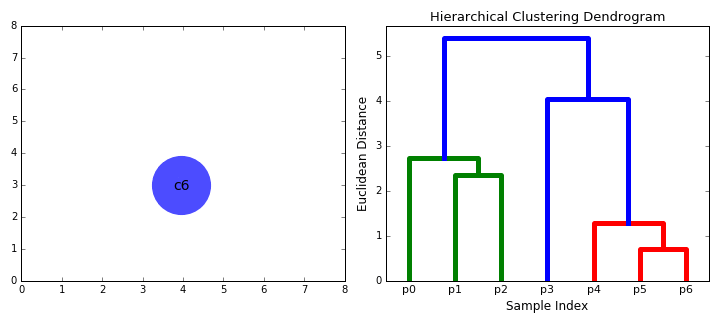
- We begin by treating each data point as a single cluster i.e if there are X data points in our dataset then we have X clusters. We then select a distance metric that measures the distance between two clusters. As an example we will use average linkage which defines the distance between two clusters to be the average distance between data points in the first cluster and data points in the second cluster.
- On each iteration we combine two clusters into one. The two clusters to be combined are selected as those with the smallest average linkage.
- Step 2 is repeated until we reach the root of the tree i.e we only have one cluster which contains all data points. In this way we can select how many clusters we want in the end, simply by choosing when to stop combining the clusters i.e when we stop building the tree!
A particularly good use case of hierarchical clustering methods is when the underlying data has a hierarchical structure.
It has a time complexity of O(n³), unlike the linear complexity of K-Means and GMM.
source: The 5 Clustering Algorithms Data Scientists Need to Know
No comments:
Post a Comment