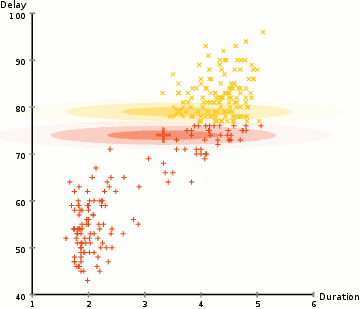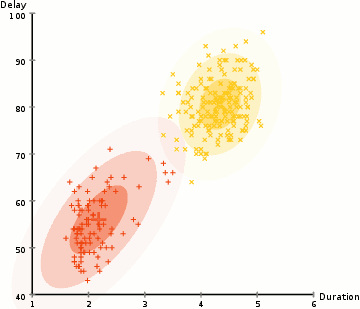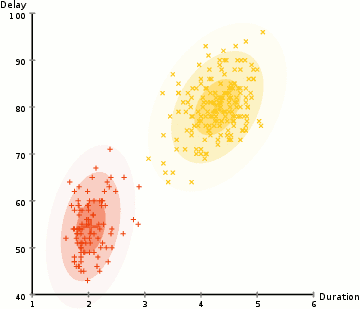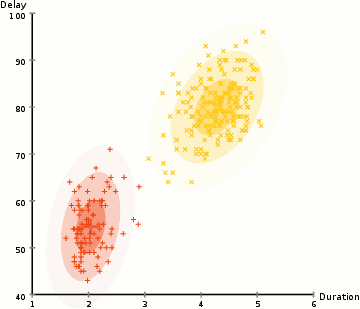
- Select the number of clusters and randomly initializing the Gaussian distribution parameters for each cluster.
- Given these Gaussian distributions for each cluster, compute the probability that each data point belongs to a particular cluster.
- Based on these probabilities, we compute a new set of parameters for the Gaussian distributions such that we maximize the probabilities of data points within the clusters. We compute these new parameters using a weighted sum of the data point positions, where the weights are the probabilities of the data point belonging in that particular cluster.
Advantage
- More flexible in terms of cluster covariance than K-Means; due to the standard deviation parameter, the clusters can take on any ellipse shape, rather than being restricted to circles.
- Since GMMs use probabilities, they can have multiple clusters per data point. So if a data point is in the middle of two overlapping clusters, we can simply define its class by saying it belongs X-percent to class 1 and Y-percent to class 2. GMMs support mixed membership.
source: The 5 Clustering Algorithms Data Scientists Need to Know
No comments:
Post a Comment