- DBSCAN begins with an arbitrary starting data point that has not been visited. The neighborhood of this point is extracted using a distance epsilon ε (All points which are within the ε distance are neighborhood points).
- If there are a sufficient number of points (according to minPoints) within this neighborhood then the clustering process starts and the current data point becomes the first point in the new cluster. Otherwise, the point will be labeled as noise (later this noisy point might become the part of the cluster). In both cases that point is marked as “visited”.
- For this first point in the new cluster, the points within its ε distance neighborhood also become part of the same cluster. This procedure of making all points in the ε neighborhood belong to the same cluster is then repeated for all of the new points that have been just added to the cluster group.
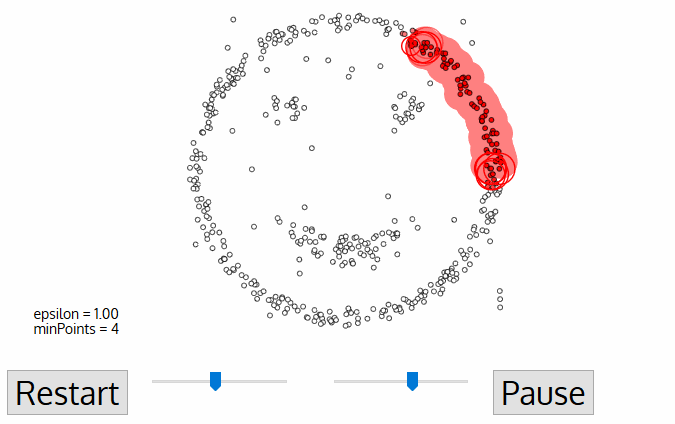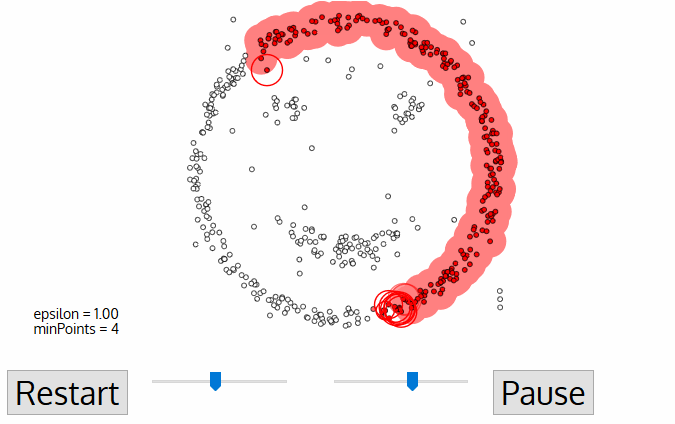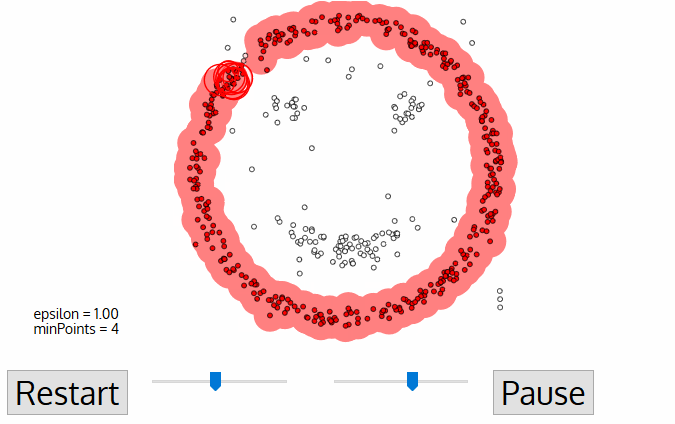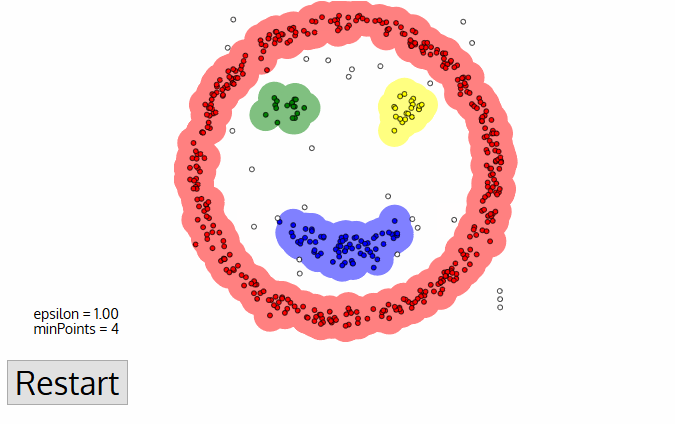
- It does not require a pre-set number of clusters at all.
- It also identifies outliers as noises unlike mean-shift which simply throws them into a cluster even if the data point is very different.
- It is able to find arbitrarily sized and arbitrarily shaped clusters quite well.
The distance threshold ε becomes challenging to estimate.
source: The 5 Clustering Algorithms Data Scientists Need to Know
No comments:
Post a Comment