The two types of Supervised Learning
- Regression: predict a continuous numerical value. How much will that house sell for?
- Classification: assign a label. Is this a picture of a cat or a dog?
Regression: predicting a continuous value
Regression predicts a continuous target variable Y. It allows you to estimate a value, such as housing prices or human lifespan, based on input data X. The data is split into a training data set and a test data set. The training set has labels, so your model can learn from these labeled examples. We have our data set X, and corresponding target values Y.
The goal of ordinary least squares regression is to learn a linear model that we can use to predict a new y given a previously unseen x with as little error as possible. Linear regression is a parametric method, which means it makes an assumption about the form of the function relating X and Y. The parameters can be estimated using gradient descent is to find the minimum error function by iteratively getting a better and better approximation of it.
A common problem in machine learning is overfitting: learning a function that perfectly explains the training data that the model learned from, but doesn’t generalize well to unseen test data. Overfitting happens when a model overlearns from the training data to the point that it starts picking up idiosyncrasies that aren’t representative of patterns in the real world. This becomes especially problematic as you make your model increasingly complex.
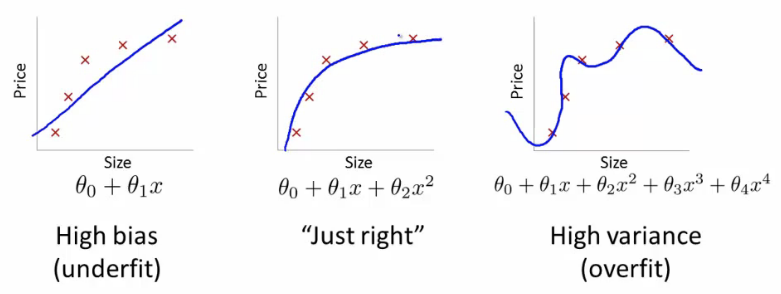
Use regularization to add in a penalty for building a model that assigns too much explanatory power to any one feature or allows too many features to be taken into account.
Classification: predicting a label
Classification is the problem of assigning new observations to the class to which they most likely belong, based on a classification model built from labeled training data.
Logistic regression is a method of classification: the model outputs the probability of a categorical target variable Y belonging to a certain class. To predict the Y label you have to set a probability cutoff, or threshold, for a positive result. The threshold depends on your tolerance for false positives vs. false negatives.
source:
No comments:
Post a Comment